
눈송이의 개발생활
[Java]자료구조 - HashMap, HashTable 본문
Hashmap이란?
- Hashing된 map
- 객체를 map에 넣는 것
💡 Map은 무엇인가?
MAP : key & value를 가진 자료구조. key와 value를 쌍으로 보관
KEY : map에 유일하게 (중복되지 않게) 존재. 동일한 key가 들어오면 기존의 쌍 대체
VALUE : 중복 가능. key를 통해서 값을 볼 수 있음
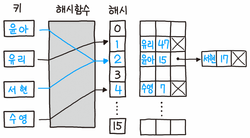
💡 Hashing은 무엇인가?
key 값을 hash function에 대입해서 계산된 결과를 주소로 사용하여 value에 접근할 수 있게 함
Java에서의 HashMap
//선언
import java.util.HashMap;
HashMap<Integer,String> map = new HashMap<>();
✅ 값 추가
// key, value
map.put("A", 100);
map.put("B", 101);
✅ 값 삭제
// key로 map의 값 제거
map.remove("A")
// 모든 값 제거
map.clear()
✅ 값 읽기
// key로 value 읽어오기
map.get("B")
// 많은 양(전체)를 출력할 때
for (Entry<Integer, String> entry : map.entrySet()) {
System.out.println("[Key]:" + entry.getKey() + " [Value]:" + entry.getValue());
}
// entrySet()은 key와 value 모두 가져올 때 사용
for(Integer i : map.keySet()){
System.out.println("[Key]:" + i + " [Value]:" + map.get(i));
}
// keySet()은 key만 가져올 때 사용
// key를 통해서 value를 찾는데 시간이 오래 걸리기 때문에 많은 양의 데이터 처리할 때는 추천X
✅ 존재 여부
map.containsKey("B") // true
map.constainsValue(200) // false
💥 Collision(충돌) 발생
Collision : 동일하지 않은 두 객체가 같은 위치에 들어가려고 하는 경우
충돌 회피 방법
1️⃣ Open Addressing
- 충돌이 생기면 다른 hash bucket에 해당 자료를 삽입하는 방식
- 데이터 개수가 적으면 2️⃣ 보다 성능이 좋다
- 배열의 크기 커질수록 연속된 공간에 데이터 저장하게 됨
- 모든 원소가 반드시 자신의 hash value와 일치하는 주소에 저장된다는 보장 ❌

2️⃣ Separate Chaining
- 해당 bucket 값을 첫 부분으로 하는 linked list로 해결
- Hash Table 방식
- 자바는 separate chaining 방식으로 hash table을 구현
Map에 공간이 없을 때
1️⃣ 리스트로 삽입하기
- 값(value)는 객체이기 때문에 리스트 자체를 마지막 bucket에 삽입할 수 있다
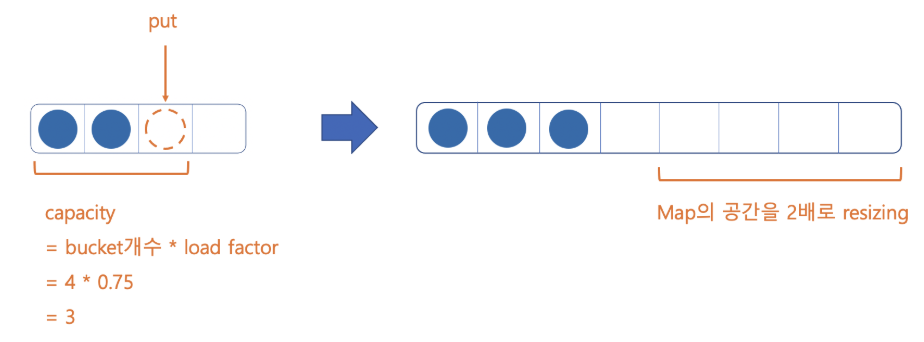
2️⃣ size 늘리기
- load factor 사용해서 map의 capacity 늘리기
- load factor : map의 크기 늘리기 위한 기준을 제공하는 수
Map<String, String> map = new HashMap<>(4, 0.75f);
- 4 → map size
- 0.75f → load factor
- 4 * 0.75 = 3 → 3번째 공간이 채워지면 hash map이 2배로 증가한다
HashMap vs. HashTable
| HashMap | HashTable |
| 빠름 but 동기화 문제 | 멀티스레드 환경에서 안전(thread-safe) |
| → multi-thread 환경에서 성능 👍 | → multi-thread 아니면 성능 떨어짐 |
| key에 null값 허용 | key에 null 허용 ❌ |
| 보조 hash 사용 → 충돌 발생 가능성 ⬇ 성능⬆ | 보조 hash 사용 ❌ |
| JAVA의 HashMap은 계속 개선 중 |
Comments